Enhancing Access to Primary Cultural Heritage Materials of India
Integrating images of literary sources with digital texts, lexical resources, linguistic software, and the web
Major activities
The project aims to enhance access to primary cultural heritage materials of India housed in American libraries by integrating them with the digital texts, lexical resources, and linguistic software in the Sanskrit Library. The project selected a small but important set of texts represented in the Indic manuscript collections at Brown University and the University of Pennsylvania, and in the Sanskrit Library’s collection of digital texts. The Brown University Library and the Rare Books and Manuscripts Library at the University of Pennsylvania made high-quality digital images of ninety manuscripts of the great Indian epic Mahābhārata, and sixty-eight manuscripts of the preeminent Vaiṣṇava text Bhāgavata Purāṇa. Sanskrit Library assistants collected catalog data and inserted that data into the XML template Scharf made in accordance with the Text-Encoding Initiative’s (TEI) manuscript guidelines, and Scharf completed editing the catalog the first week of May 2012. Scharf and Amey Huchins, the catalog librarian at the Rare Books and Manuscripts Library at the University of Pennsylavania, worked out parameters to map the completed catalog data onto the standard MaRC records used by libraries. Bunker is using this mapping to write code to transform the TEI-conformant XML catalog records to standard MaRC records for inclusion in the Penn Library catalog. He is also writing a sophisticated search interface that will provide access to manuscripts by way of a number of parameters including author, title, scribe, place, and text contained in passages transcribed. The lists of authors, titles, scribes, places, and other significant terms enrich the information provided by major Sanskrit lexical sources currently available, and constitute an additional lexical source that will be added to the Sanskrit Library’s multi-dictionary interface.
Bunker developed the Sanskrit Image-Text Alignment interface (SITA) that facilitated correlation of manuscript page boundaries with the corresponding digital text by a project assistant. Figure 26 shows the table of contents with the second image of UPenn 490 selected. Figure 27 shows on the left a section of text on the recto of folio 1 of the manuscript marked at its beginning and end by small red brackets correlated with a selection of digital text highlighted in grey on the right. The selection (MBh. 12.47.1-3) is the opening of the Bhīṣmastavarāja (the praise of Viṣṇu by the grandfather Bhīṣma) which occurs in the twelfth book (parvan) of the Mahābhārata. The text in red in the manuscript image that precedes the open bracket is identified as a benediction in Figure 28; the passage does not have corresponding text in the digital edition since the digital edition does not include invocations. Figure 29 shows an XML file of text-image alignment and annotation records. The XML annotation records allow multiple manuscript images to be linked to searchable digital texts thereby allowing focused access to individual pages in manuscript images that contain the sought passage.
The Sanskrit Library catalog of the manuscripts in the project provides access to the manuscript images, directly through an index of folios and indirectly through passages included in the manuscript catalog. Figure 30 shows a sample HTML page containing the catalog entry for UPenn 490. Clicking on ‘f. 1v’ beside the heading ‘Incipit’ on p. 1 of the entry brings up the verso of the first folio as shown in Figure 33. Similarly every reference of ‘f.’ followed by a folio number and ‘r’ or ‘v’ (for recto or verso), including those in the complete table of digital images shown in p. 3 of Figure 30, is a link to an image of the corresponding manuscript page. Clicking on the text under the heading, ‘Incipit,’ near the beginning of the catalog entry locates the pointer at the beginning of the first sentence or verse of the work in the transcription section of the catalog entry shown in p. 4 of Figure 30. An alternate view of the transcription section that shows the layout of lines exactly as on the manuscript page, where sentence and verse structure were regularly ignored, is shown in Figure 31. Clicking on a bibliographic reference such as “(MBh. 12.47.1ab),” either in the catalog data section (Figure 30, p. 1) or in the transcription section (Figure 30, p. 3), opens the file containing the corresponding digital text and locates the pointer at the referenced passage, as shown in Figure 32. The digital text and all transcriptions in the manuscript catalog are displayed in Devanāgarī by selecting the appropriate parameter in the preferences dialog box. When passages are sought in the search interface, a list of links to the manuscript pages on which the sought passage occurs is generated dynamically. Clicking a link displays the manusript page as shown in Figure 34. The red brackets in the manuscript image indicate the beginning and end of the passage containing the sought passage as the passage was previously correlated with the digital text manually using SITA (Figure 27).
In addition to the manual alignment of the text in manuscript images with corresponding digital text just described, the project explored the possibility of utilizing automated techniques of text-image alignment and word-spotting. Oliver Hellwig, who developed OCR software with 99% accuracy on well-printed Hindi texts, tested his software on some of Sanskrit Library manuscript images. His initial attempt provided partial recognition, but also led to the observation of the need for some preprocessing. Donglai Wei, a former undergraduate student in the Division of Applied Math at Brown University and now a graduate student at M.I.T., initiated preprocessing of manuscript images in the pilot manuscript project. First he developed the crop program that splits original digital images of paired manuscript pages into individual page images and produces TEI-conformant XML references to them to be inserted in the XML manuscript catalog entry files. Next he stripped colored border lines and produced a polarized image, as shown in Figure 35.
The initial exploration of OCR on manuscript images undertaken during the Sanskrit Library pilot project confirms the expected, that viable text-image alignment software requires the inclusion of linguistic and textual constraints and human validation. Besides the SITA program that facilitates human annotation of text-image alignment, the Sanskrit Library has developed other interfaces that facilitate human production and validation of technical and image data. Bunker developed the Siva program that checks the internal and external references in catalog entry XML files and generates reports to facilitate correction. He also developed the Folio program that produces an interface that allows one to check the correlation of the cropped images produced by Donglai Wei's crop program with the original images. Figure 36 shows miniature images of the crops displayed immediately to the right of originals so that an assistant can easily spot where adjustments in correlation are necessary, for example here where the crops are in reverse order.
Project personnel
- Peter M. Scharf, Project Director
- Ralph E. Bunker, Assistant Professor (MUMRI)
- Matthias H. Ahlborn, Post-Doctoral Research Associate
- Anupama Ryali, Post-Doctoral Research Associate (UoHyd)
- Toke L. Knudsen, Post-Doctoral Research Associate
- Benjamin Fleming, Post-Doctoral Research Associate (UPenn)
- Susan J. Moore, Post-Doctoral Research Associate
Grant details
- period: 1 July 2009 -- 30 December 2013
- funding agency: National Endowment for the Humanities, Division of Preservation and Access
- funding: $301,540
- awardee: Brown University
- subawardee: Maharishi University of Management Research Institute (MUMRI)
- subawardee: University of Hyderabad (UoHyd)
- contractee: University of Pennsylvania (UPenn)
Figures
Figure 26
Sanskrit Library text-image alignment software: TOC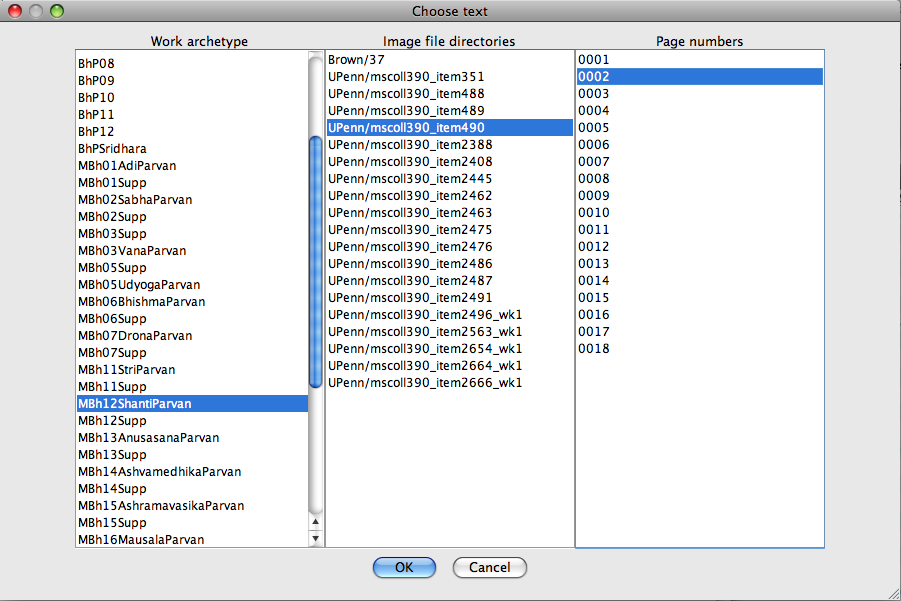
Figure 27
Sanskrit Library text-image alignment software: correlation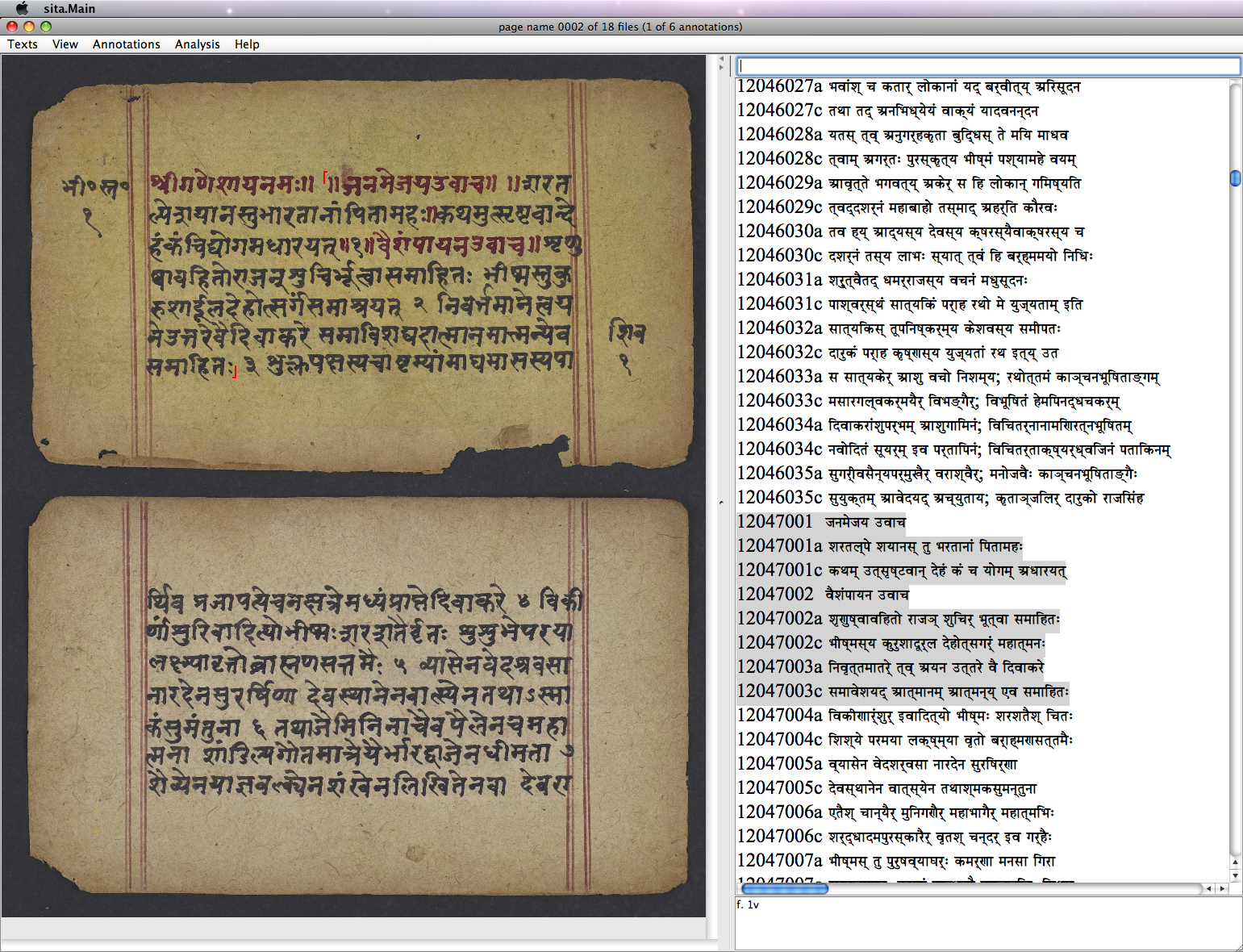
Figure 28
Sanskrit Library text-image alignment software: variation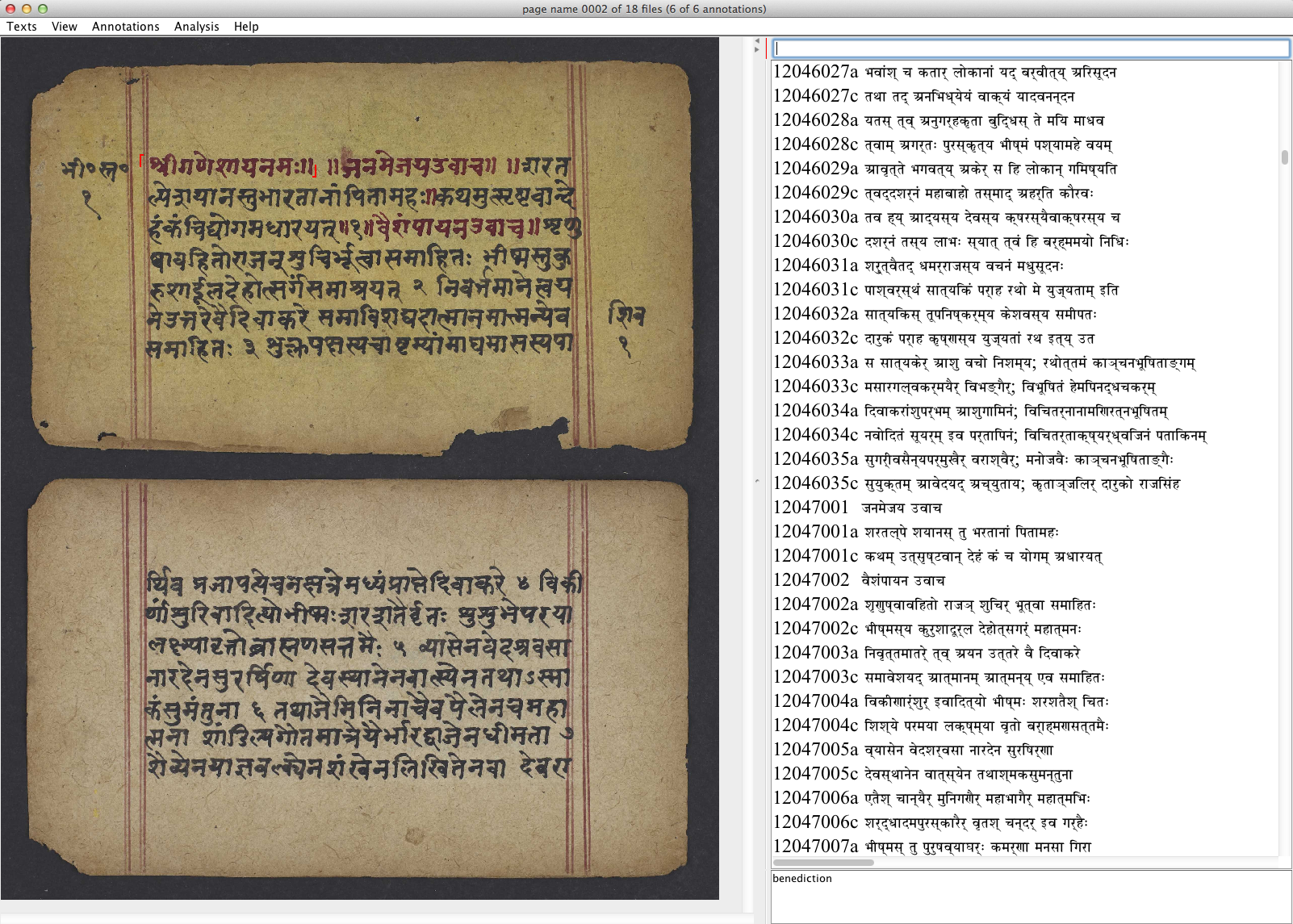
Figure 29
Sanskrit Library XML image-text alignment data
Figure 30
Sanskrit Library manuscript catalog entry: text structure
Figure 31
Sanskrit Library manuscript catalog entry: ms. layout
Figure 32
Sanskrit Library digital text
Figure 33
Sanskrit Library cropped image display
Figure 34
Sanskrit Library annotated image display
Figure 35
Sanskrit Library stripped and polarized image display
Figure 36
Cropped image — original image correlation validation interface